
Here at ControlUp we periodically perform big data research on usage metrics in the wild. Our product lets systems administrators compare their IT metrics to the “community”, which is the aggregate of IT systems in organizations being managed by ControlUp. With the permission of our customers, we provide benchmarks on a variety of metrics, such as logon duration, application load time, protocol latency, and application usage. The data includes resource allocated to each virtual machine and what was actually used.
For this research
- Is there really a throw-more-hardware-at-problem approach to solving performance issues?
- If servers are not provisioned just right, are they over- or under-provisioned? By how much?
- Does adding more resources (vCPU & memory) = better performance?
- Do new versions of OSes requires bigger iron?
- How do people navigate the waters to *reduce* resources from a system that “ain’t broke”?
As far as we know there has never been a big data analysis done to answer these questions. So off we went.
- From our universe of data on VM performance, we excluded unreliable datasets (trial systems), incomplete datasets (gaps in the 60-day collection period), and statistically insignificant datasets (not enough data points), and we ended up with 148,233 VMs running in 943 organizations.

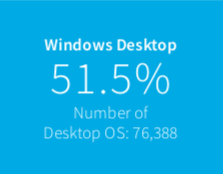
- We categorized each VM into “Desktop OS” and “Server OS”. The former are end user sessions and the latter are server workloads, such as healthcare and financial applications. Coincidentally, our data happened to provide us roughly a 50-50 split.
 .
. 
- We then took each VM’s resource usage information and discarded spikes. For example, for processor
utilization we eliminated top 5% of CPU utilization.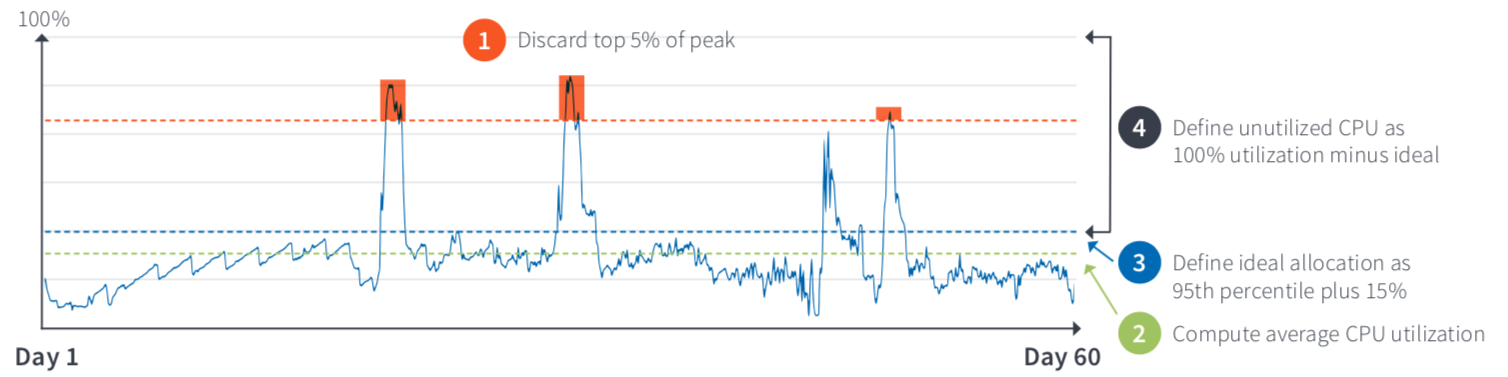
- We applied the following provisioning best practices guidelines to calculate what a VM’s right-sized provisioning should be, based on actual usage.

- We then subtracted that Ideal Provisioned value from Actual Provisioned value, and placed that one VM into one of several “buckets” of provisioning accuracy; from under-provisioned to right-sized to over-provisioned (and levels within).
vCPU
RAM
- Lastly, we rinsed and repeated these steps for 148,232 more VMs.
What did we find?
The report presents extensive results, but here are some highlights.
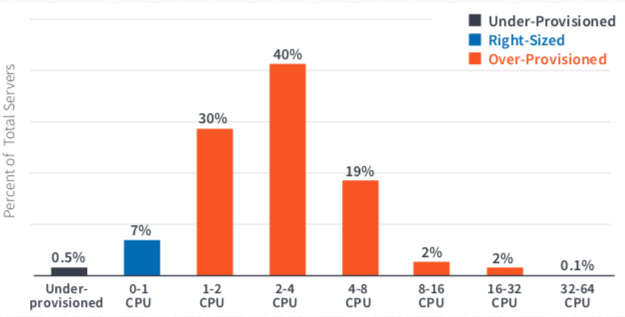
- We found 93% of the server VMs had vCPU over-provisioning, by an average of 3.4 vCPUs. Desktop VMs provisioning didn’t do much better.
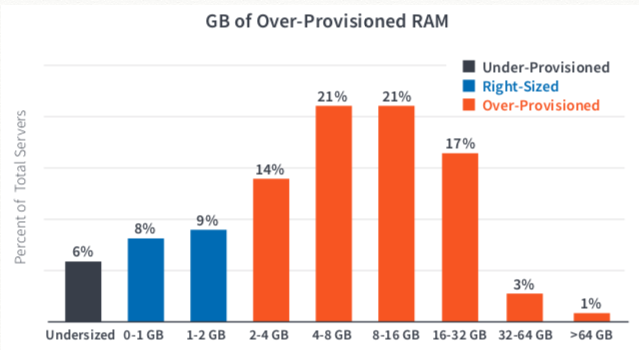
- On the memory side, 77% of the server VMs were provisioned with RAM that was never utilized, by an average of 11.7GB!
We also sliced the data based on OS versions and had 3 key takeaways:
a) Newer OSes are indeed more efficient than its recent predecessors (values in blue in the chart below).
b) It appears people know that fact and
c) The ratio of over-provisioning (orange line) still remains crazy high.
Again, here are some server results, and the report has detailed statistics on both server and desktop OSes.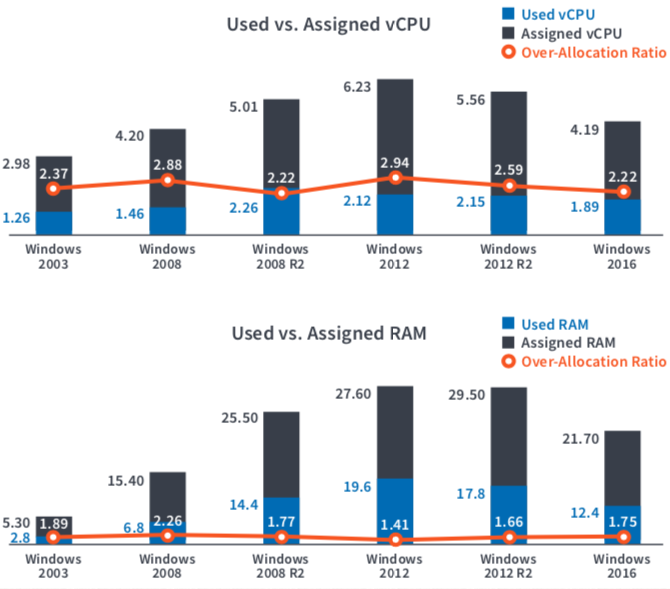
Why does this matter?
For memory it’s straight forward — the cost of over-provisioning is the cost. Allocating 1GB of RAM blocks off that memory from other VMs running on that hardware. Based on this concept, we found an average of $118 spent on memory over-provisioning per VM, which added up to $26.4m across our data set.
The costs of CPU over-provisioning is a bit more nuanced. While there is obviously a cost impact of buying more processors than needed, the actual dollar value is hard/impossible to measure because each physical core is shared across VMs. While CPU schedulers generally do a good job, there is a performance penalty here. The paper discusses this in detail but at a high level, allocating more vCPU than needed is analogous to asking a restaurant for a table for 8 when you have a party of 2 — you’ll wait longer for the table and other patrons will suffer. (Yes, NUMA alleviates this to an extent but…read the paper 🙂
What do I do about it?
Touching a system that “ain’t broke” can be a risky proposition. And instead of adding, removing resources? That’s crazy talk! In the paper we discuss some practical and prescriptive steps in navigating these waters.