When the cloud fails, what does your IT team do?
What happens when IT support tickets suddenly skyrocket, all reporting a similar issue with a business critical app or service? Your team may start asking: “Is it the network?” “Is it the application?” “Is this a known issue?” “Is it us?”
When global cloud outages occur, like recent Azure or AWS disruptions, IT teams are often left scrambling. The first several hours may be spent trying to understand the scope of the issue, searching for fixes, and identifying workarounds. Meanwhile, productivity dips and frustration spikes.
During a recent Proof of Concept (PoC) using ControlUp ONE, we witnessed real-time evidence of these challenges. A simple synthetic test, running on a key SaaS application, provided immediate and undeniable clarity: failures were intermittent, but they were happening over nearly three hours and largely from one region. This wasn’t a problem IT could fix, but thanks to synthetic monitoring, they were the first to know.
This is where the workplace runs itself: ControlUp’s early warning system provided immediate, undeniable clarity, allowing the team to notify potentially impacted users, reduce tickets, and provide certainty within the chaos.
How We Set Up the Synthetic Test
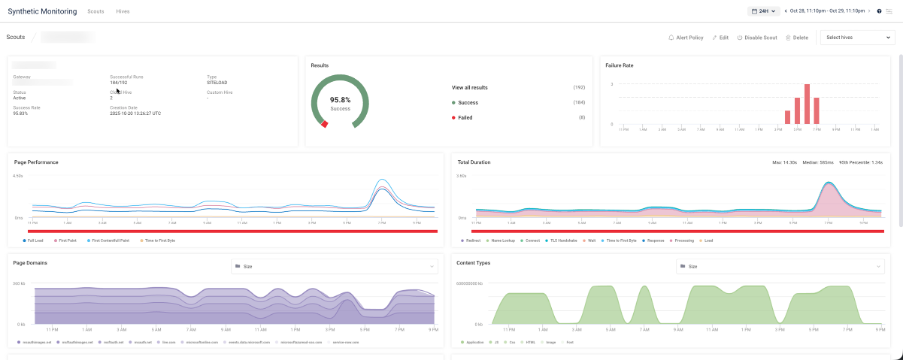
In the PoC environment, we configured a synthetic scout to test a business-critical SaaS application every 15 minutes from two regions: one in Northern Europe and another in Western Europe. This test was set up to attempt to load a page and measure performance metrics, such as response time and total duration.
Detailed Results Lead to a Big Discovery
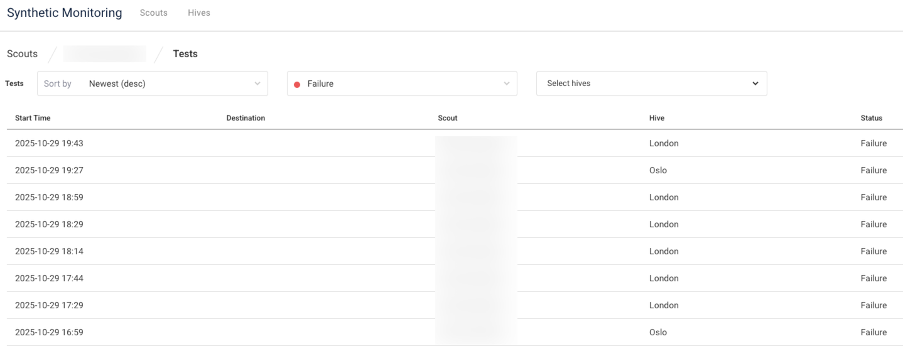
When we initially reviewed the test results, everything looked fine: a 95.8% success rate and solid performance overall. However, the detailed view told the true story, revealing several test failures between 16:59 and 19:43—indicating nearly three hours of partial disruption.
The user might have noticed slow or failed logins and called IT for help troubleshooting. However, synthetic monitoring gives IT immediate visibility to the issue, allowing them to develop a workaround or communication plan for impacted users.
The Bigger Picture: Cloud Outage Impact
What makes this case particularly interesting is that the timing of these failures matches the large-scale Azure and AWS outage that affected customers worldwide on the same day. Both providers confirmed network and routing disruptions impacting various regions and services, including front-end access and authentication.
This correlation highlights the true value of synthetic monitoring: even when the problem lies within a global cloud provider’s infrastructure, you still see its local impact—which regions are affected, when the degradation started, and when it recovered.
The Metric that Matters During Global Downtime: Mean Time to Awareness (MTTA)
IT operations often focus on improving Mean Time to Resolution (MTTR), i.e. how quickly a problem is fixed. It’s a meaning metric that allows you to take direct action to resolve an issue.
But what metrics should you watch in cases where you can’t fix the issue?
When a disruption originates outside of the network or is related to a global outage; awareness is key. By focusing on “Mean Time to Awareness (MTTA),” IT teams can respond intelligently, rather than react blindly.
Synthetic monitoring is a powerful tool when it comes to lowering MTTA. Here’s how it helps improve IT efficiency, streamline operations, and increase productivity:
- Know about issues before users start reporting them
- Avoid wasting hours troubleshooting infrastructure you don’t control
- Communicate proactively with stakeholders and end users
- Escalate confidently to the responsible provider with factual data
In short, synthetic monitoring doesn’t just enable faster fixes, it enables an empowered IT team that understands what’s happening and how to take action.
Achieving Autonomous Monitoring: How to Go Further
While this PoC setup was intentionally simple, a few improvements could make it even more powerful in a production environment:
- Shorten the test interval: Running every 5 minutes instead of 15 provides higher temporal accuracy to pinpoint outages.
- Upgrade to a Web Transaction test: Simulating a full user workflow (login, search, submit) provides deeper diagnostic detail on what fails first.
- Automate ITSM integration: Connect synthetic results to your ticketing system (for example, via ServiceNow) to automatically create incidents when thresholds are exceeded.
Why This Matters for IT Operations
Synthetic monitoring provides an early warning system. Real-user analytics show the impact; synthetic tests reveal where and when the problem starts even when it’s a global cloud provider issue.
In this PoC, a single scout provided three hours of visibility into a widespread Azure and AWS outage. Proactive monitoring allows IT to focus on metrics that matter and confidently navigate the path forward during downtime.
Synthetic monitoring enables IT to find and mitigate issues, stay ahead of frustration, and confidently act—all before a user calls for support.
Want to see it in action? Schedule a personalized demo with one of our DEX pros.