
Your IT team gets 247 alerts before lunch. Another system crashes during dinner. Someone’s phone rings at 3 AM with yet another “critical” notification that suddenly turns out to be nothing.
Maybe it sounds too familiar…?
Burnout has become the far-from-insignificant productivity killer in IT departments everywhere. By the time your best engineers and IT personnel start missing deadlines, making unusual mistakes, or updating their LinkedIn profiles from the quietest corner of the office, you’re already in trouble.
The numbers tell a brutal story: 71% of full-time employees report they’re burnt out. The human cost runs even deeper.
But there’s a way forward that requires more than hiring an army of new engineers or accepting chronic exhaustion as “just part of the job.”
This article includes eight actionable techniques to transform how your team handles alerts, manages workloads, and maintains their energy (without compromising system reliability).
Let’s get to it.
What is IT Burnout and its Consequences?
IT burnout represents a state of physical, emotional, and mental exhaustion resulting from prolonged exposure to chronic workplace stressors specific to technology roles.
The condition develops when professionals face continuous high-pressure situations – managing critical infrastructure failures, responding to security incidents, maintaining legacy systems while implementing new technologies, and/or handling competing priorities from multiple stakeholders without sufficient resources or recovery time.
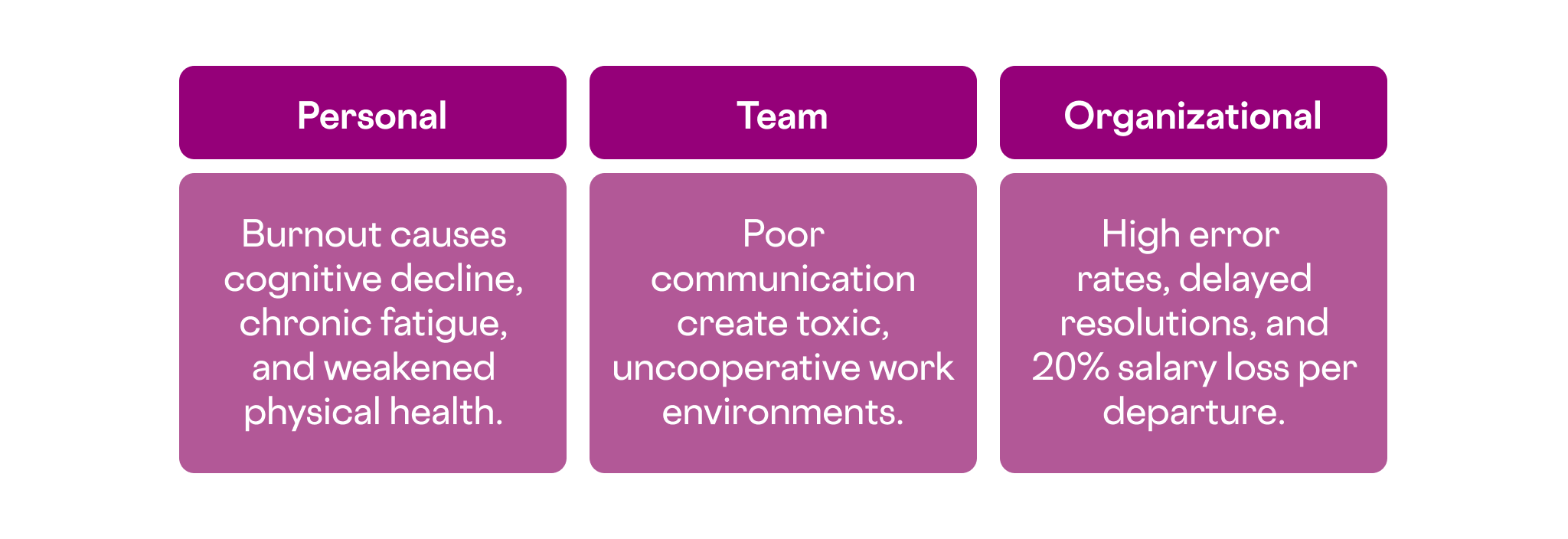
The consequences cascade through three distinct levels.
- Personally, IT professionals experience decreased cognitive function, chronic fatigue, and increased susceptibility to physical illness.
- Team dynamics deteriorate through knowledge hoarding, reduced collaboration, and communication breakdowns, creating toxic work environments.
- Organizationally, burnout drives high error rates in production deployments, extends incident resolution times, and costs companies up to 20% of an employee’s salary per departed senior engineer when factoring in recruitment, training, and lost productivity.
If these consequences sound familiar, your team is likely already feeling the strain. But change begins with a clear plan. To protect your talent and your business, we’ve compiled a list of the eight most actionable and effective ways to reduce alert fatigue, improve work-life balance, and make ‘always-on’ a thing of the past.
Eight Actionable Strategies to Battle IT Burnout
- Recognize Early Warning Signs of IT Burnout
- Strengthen On-Call Rotation to Prevent Alert Fatigue
- Automate Routine Monitoring to Reduce Manual Overload
- Prioritize Smart Alerting to Eliminate Noise
- Handle Incident Response Using Intelligent Automation
- Hire Strategically to Distribute IT Workloads
- Encourage Work-Life Balance Across IT Operations
- Provide Continuous Training to Build Team Resilience
1. Recognize Early Warning Signs of IT Burnout
You can spot burnout brewing before it explodes into resignations and system failures. Watch for engineers who early on showed enthusiasm but now go quiet in meetings, stop volunteering for interesting projects, or consistently work through lunch at their desks. Performance metrics reveal the pattern too – ticket resolution times creep up, code commits decrease, and documentation gets skipped.
Physical symptoms manifest as frequent headaches, sleep disruptions, and increased sick days. Emotional indicators include irritability over minor issues, pessimistic comments about company direction, and withdrawal from team social activities.
The crux of the matter lies in catching these signals before they escalate – seemingly competent professionals can deteriorate rapidly once burnout takes hold.
What to do:
- Schedule monthly one-on-ones focused specifically on workload and stress levels, creating a safe space for honest feedback without judgment.
- Implement anonymous pulse surveys every quarter to track team morale trends and identify concerning patterns before they become a surprise.

2. Strengthen On-Call Rotation to Prevent Alert Fatigue
Alert fatigue doesn’t happen by accident. It’s the result of broken systems, disconnected tools, and workflows that haven’t kept pace with scale. The main culprits:
- Noisy, redundant data – When everything generates an alert, nothing matters.
- Tool sprawl – Dozens of dashboards that don’t talk to each other create more problems than they solve.
- Crying wolf – False positives and cascading alerts train teams to ignore warnings.
- Manual grunt work – If humans are still the first responders for every ping, burnout is inevitable.
- Badly tuned thresholds – Generic settings that trigger on normal behavior waste everyone’s time.
- Junk alerts – Low-impact notifications that could wait, or shouldn’t exist at all.
How to prevent it? Start with rotation schedules that don’t grind people down; swap on-call duties every week or two at most, and build in real recovery time between shifts. Set explicit boundaries around after-hours contact, only page for genuine emergencies that impact revenue or customer data, never for non-critical monitoring alerts that can wait until morning.
Clear escalation paths eliminate confusion during incidents:
- Primary on-call handles initial triage (15-minute response)
- Secondary backup activates for complex issues (30-minute response)
- Management escalation triggers after 60 minutes
- Post-incident reviews happen within 48 hours
That said, make sure you include both base pay and per-incident bonuses as compensation. This structure ensures no single person carries the entire burden while maintaining rapid response capabilities.
3. Automate Routine Monitoring to Reduce Manual Overload

Automating repetitive checks transforms your team from reactive firefighters into proactive problem-solvers. Start with setting up digital workplace automations for the tasks that eat the most time, like log reviews, disk space monitoring, certificate renewals, and backup verifications. These mundane activities consume 40% of an average IT professional’s week yet require minimal human judgment.
Real-time visibility transforms chaos into clarity by showing your entire infrastructure status on unified dashboards. Engineers need immediate answers about system performance, user experience metrics, and resource utilization without jumping between a dozen different monitoring tools.
When everyone sees the same live data, finger-pointing stops and collaborative problem-solving begins. The ControlUp ONE digital employee experience (DEX) platform saves the day with real-time monitoring, allowing you to consolidate virtual desktop infrastructure, physical endpoints, and cloud resources into a single pane of glass, letting IT teams spot performance degradation before users complain.
4. Prioritize Smart Alerting to Eliminate Noise
Smart alerting means your team only gets notified about issues that genuinely matter. Start by auditing every alert from the past month – if an engineer dismissed it without action more than twice, it needs reconfiguration or removal. Strive to devise alert groupings that consolidate related notifications, implement progressive thresholds that account for normal usage patterns, and add context about business impact directly into alert messages.
Modern monitoring platforms can dramatically reduce alert fatigue through intelligent filtering. ControlUp’s advanced alerting system utilizes customizable thresholds and smart triggers that adapt to your environment’s baseline performance, sending notifications only when metrics deviate from normal patterns.
The platform’s alert management capabilities let you set multi-condition triggers, schedule maintenance windows to suppress non-critical alerts, and create escalation rules based on severity levels – further stemming the flood of unnecessary notifications that exhaust IT teams. This approach transforms your alert stream from a firehose into a manageable flow of actionable insights.
5. Handle Incident Response Using Intelligent Automation
Intelligent automation reduces incident response from hours to minutes by executing predefined remediation workflows the moment problems arise. Your team defines the fix once, then the system handles similar issues automatically – restarting frozen services, clearing cache buildup, reallocating resources, or rolling back problematic updates without human intervention.
ControlUp’s automated actions trigger based on customizable thresholds and conditions, executing PowerShell scripts or API calls to resolve common issues like high CPU usage, memory leaks, or session disconnections.
For example, when a virtual desktop hits 90% CPU utilization, the platform can automatically add resources, notify the user about the fix, and log the incident for review – turning a potential 2 AM emergency into a non-event that resolves itself.
6. Hire Strategically to Distribute IT Workloads
Strategic hiring goes beyond filling empty seats – it requires mapping current skill gaps against upcoming projects and anticipated growth. Calculate your true staffing needs by tracking overtime hours, delayed projects, and deferred maintenance tasks.
If your team consistently logs 50+ hour weeks just to maintain the status quo, you need additional headcount, not more efficiency initiatives.
That said, an Employer of Record provider can make the hiring process super easy for you by handling local compliance, payroll, and benefits administration. This lets you focus on finding the right talent rather than handling complex international employment laws.
Focus recruitment on complementary skills rather than duplicating existing expertise:
- Cloud architects to modernize legacy systems
- Security specialists to handle compliance requirements
- DevOps engineers to build automation pipelines
- Junior staff to handle tier-1 support tasks
- Documentation specialists to capture tribal knowledge
This distributed approach prevents any single person from becoming an irreplaceable bottleneck.
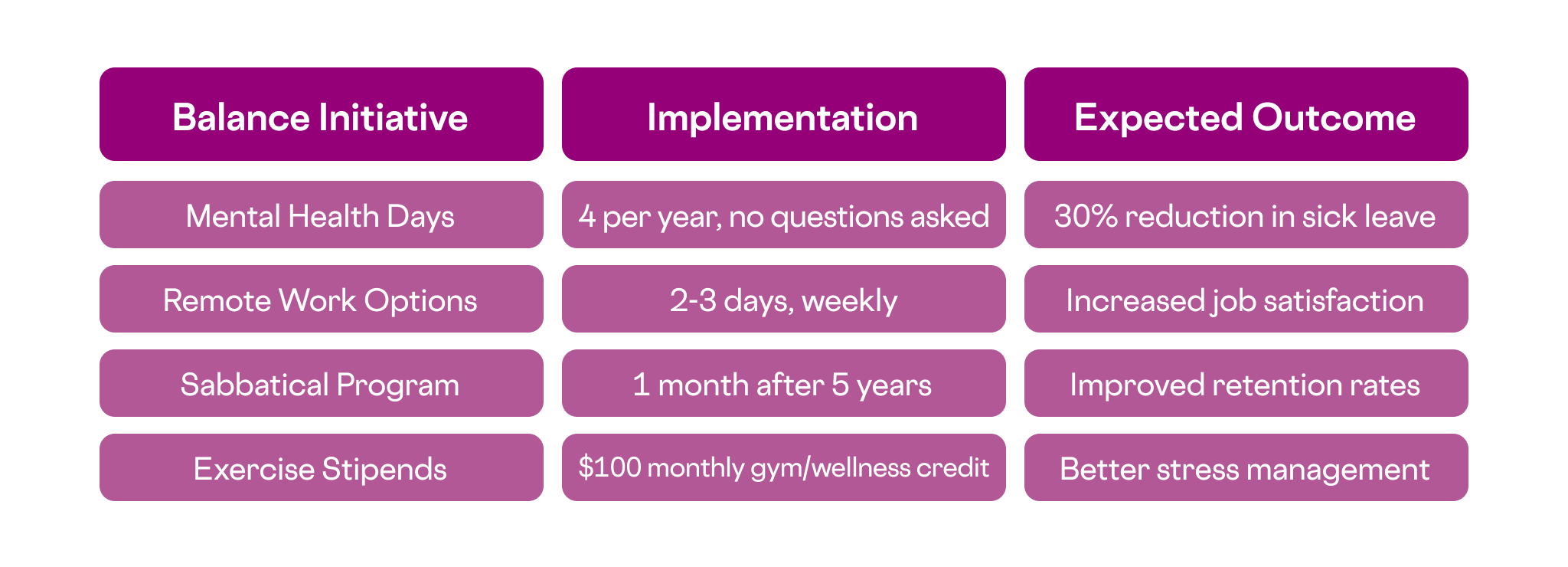
7. Encourage Work-Life Balance Across IT Operations
Work-life balance requires intentional policies that protect personal time. Implement “no meeting Fridays” for deep work, mandate lunch breaks away from desks, and establish email blackout periods after 6 PM. Flexible scheduling lets night owls handle evening maintenance windows while early birds tackle morning deployments, matching natural energy patterns to work demands.
8. Provide Continuous Training to Build Team Resilience
Continuous training prepares your team for evolving technologies while preventing the anxiety that comes from feeling left behind.
Allocate 10% of work hours to learning – whether through online courses, vendor certifications, or internal knowledge sharing sessions. Engineers who regularly update their skills report 45% less stress when facing new technical challenges.
Create structured learning paths that align with both organizational needs and individual career goals. Pair senior engineers with juniors for mentorship, rotate team members through different technology stacks, and celebrate certification achievements publicly. When your team knows they’re growing professionally, they’re more likely to see challenges as opportunities rather than threats to their competence.
For example, the ControlUp Academy helps IT pros deepen their expertise in DEX, empowering them to become strategic problem-solvers and proactive architects of smarter, more resilient IT environments. That kind of confidence and clarity can turn stressful workdays into consistently smooth and productive ones for the whole organization.
Stopping the Cycle of IT Burnout
IT burnout feeds on endless alerts, impossible deadlines, and that crushing feeling of never catching up. The path forward requires deliberate action – automating the repetitive stuff, sharing the on-call burden fairly, and giving your team room to breathe and grow.
Smart monitoring tools eliminate the noise. Strategic hiring spreads the load. Real work-life boundaries protect sanity. Your engineers chose this field because they love solving problems. Give them the space and support to do exactly that without sacrificing their well-being.
