
How do you measure user experience (UX) in a Citrix or VDI environment?
When I worked with end users I used various methods to measure the quality of their experience. If the user was nearby, I would visit them and actually watch them work, otherwise, I’d do some sort of screen share. I found it fascinating to observe users at work. I noticed the pauses and lags in their applications as they queried a database or accessed a file share.
Some of these lags were pretty bad. I also observed that when the app frequently misbehaved, users became accustomed to the delays. They began to accept the inconvenience, making it a normal part of their day.
If you value your users’ experience and your organization’s efficiency, optimizing their UX is essential. Actually seeing what users do in their apps and profiling the delays can help provide optimization opportunities. For example, if the application is accessing a file share a lot, ensuring that file share is operating as fast as possible to provide those requests is critical.
However, identifying and measuring these workflows is very time consuming. Surely, there must be a better way…

Citrix developed a user experience metric called ICA Round Trip Time (ICA RTT) to help solve this. It measures how long it takes an application to respond to input. That is, when a user clicks a button or types on the keyboard, the stop watch begins, and it stops when the user interface (UI) provides the response, like displaying a menu or the characters you typed.
![]()
Microsoft also took on this challenge. As of Windows 10 1809+ or Server 2019 and newer, Microsoft developed a new metric called User Input Delay. This counter is very similar to Citrix’s ICA RTT. It also measures the time from user input (like the aforementioned keyboard or mouse activity, for example) and to UI response.
So, how do these two metrics operate? And how do they differ? Which is more actionable for IT?
ICA Round Trip Time (ICA RTT)
ICA RTT has 2 components that combine to provide a result.
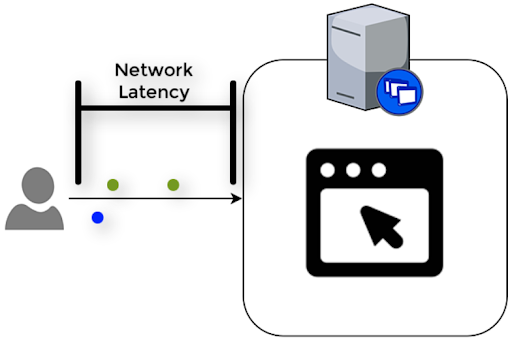
- The first is network latency. Network Latency is the amount of time it takes for your Citrix Receiver/Citrix Workspace App to send a network packet to the server and receive a response.
- The second component is the time it takes the application to process the user’s input and return the result.
ICA RTT = Network Latency + Application Response Time
The Challenges of ICA RTT
Challenges and drawbacks are always expected. Here are a few to be aware of:
Drawback #1: Sampling delay
The first is the sample rate. ICA RTT, by default, is sampled about every 15 seconds. Network latency as measured by the Citrix Performance Counter is called “ICA Last Latency” and is sampled at 20-second intervals.
This causes these two values to be out of sync when you ask for their measurements. Additionally, real-time fluctuations in network latency or lag in actions within an application can cause these two values to show wild discrepancies, leading to the age old question: Why is my ICA RTT less than my network latency? That should be impossible!
In reality, ICA RTT isn’t lower, but at the time of the sample it was, and since then conditions have changed. You’ll need to wait for the next sample and hope that conditions haven’t changed (too much!).

To test ICA RTT, I created a script that queries the ICA RTT and ICA Last Latency values, as well as a script that measures my ping time to my endpoint. ICA RTT stated a result of 1037ms and network is stated 39ms. If at this moment you sampled these metrics you’d be misled and might think that the application was the cause of the delay, but in the ping window we can clearly see the delay is with the network (around 1000ms). With delays like this, it is almost impossible to determine what the user is actually experiencing.
Drawback #2: Session-level granularity
ICA RTT is only available on the session level. If you use session sharing applications you will be unable to determine which application is the cause of the delay. ICA RTT will provide you with only an overall number for the entire session.
Drawback #3: No clear breakdown
Is the delay due to the network or the application? Even if the intervals were the same time duration, the ICA RTT doesn’t break down the metric any further. Network and application performance can be wildly variable on the best of days and network issues can actually *mask* network issues. What do I mean?
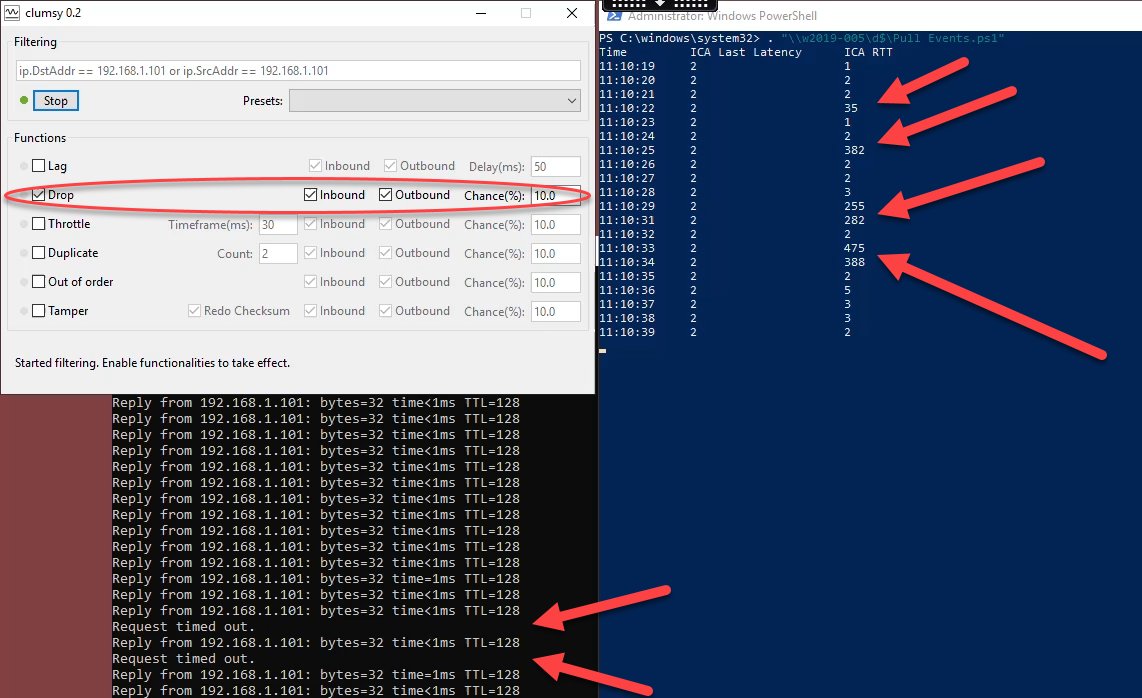
Simply dropping packets can cause ICA RTT to vary wildly, even if the application is responding well and the network is experiencing low latency. But, without the ability to observe performance details it’s impossible to determine why we are getting such high deviation from one measurement to the next. Network stats may look good, but ICA RTT is showing something is amiss. If ICA RTT could report purely on an application it would be extremely easy to deduce network is our issue.
Drawback #4: Non-native metric
The ICA RTT metric is not a native Windows Performance Counter metric. It is only available by querying WMI. WMI has some challenges of its own. The WMI repository can become bloated, increasing the CPU cost to pull data from it. Further, WMI can become corrupted, making it unusable until the repository can be rebuilt.
Can ICA RTT be improved?

Yes! You can leverage group policy options to improve ICA RTT, specifically:
- ICA round trip calculation interval
- ICA round trip calculations for idle connections
By modifying these values, especially the interval, you can get closer to getting the information you need, the performance of the application in real time.
If you are running a Citrix session, ICA RTT is also available for all operating systems, not just recently released ones.
User Input Delay
This performance counter measures in real-time how long a process takes to respond to user input (such as mouse or keyboard). In most cases, it is able to accurately measure how long it takes the UI to respond to input (with a granularity of 16ms). User input delay allows you to accurately determine if the application is operating efficiently.
Here’s my version of how this metric works, but Microsoft has also explained this metric in technical details here.
By clicking on a UI element, like the menu title, the application will try and render the menu contents. The metric measures from the point of the click/key press to when the UI returns.
This measurement occurs on the process level, giving you incredibly detailed process performance information. Microsoft than aggregates the values of all processes and sets the highest value as the session metric. For the computer, ControlUp returns the Max Input Delay, which is the highest value across all sessions, and Average Input Delay, which is the average of all the values across all the sessions.
As an example, I click on the File menu in an application.. This application does some processing which takes time. It then returns the contents of the menu. At the point of click the timer begins. One the processing is complete and the menu is returned, the timer stops and the result is returned.
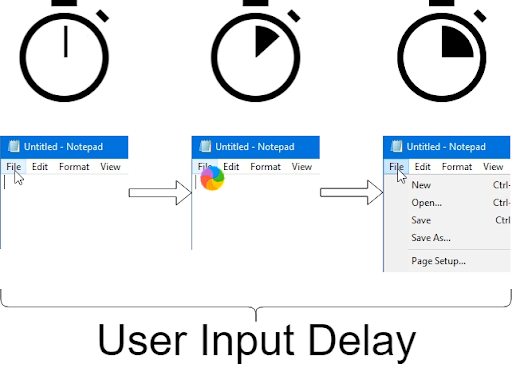
By measuring the process in this way we can easily and immediately discover if the delay is with the application or something else. If a user is performing an action where you observe a delay using the User Input Delay metric, you can instantly address that delay via your Citrix or Windows for Virtual Desktop (WVD) server and absolve the network of blame (at least between the server and the endpoint).
And eliminating suspects from contention, quickly and efficiently, can expose the root of a problem much faster.
What User Input Delay Looks Like in Practice
The best way to demo User Input Delay is with ControlUp, which has the User Input Delay metric built in and can display it in all 3 views: the Process view, the Session view and the Computers view.
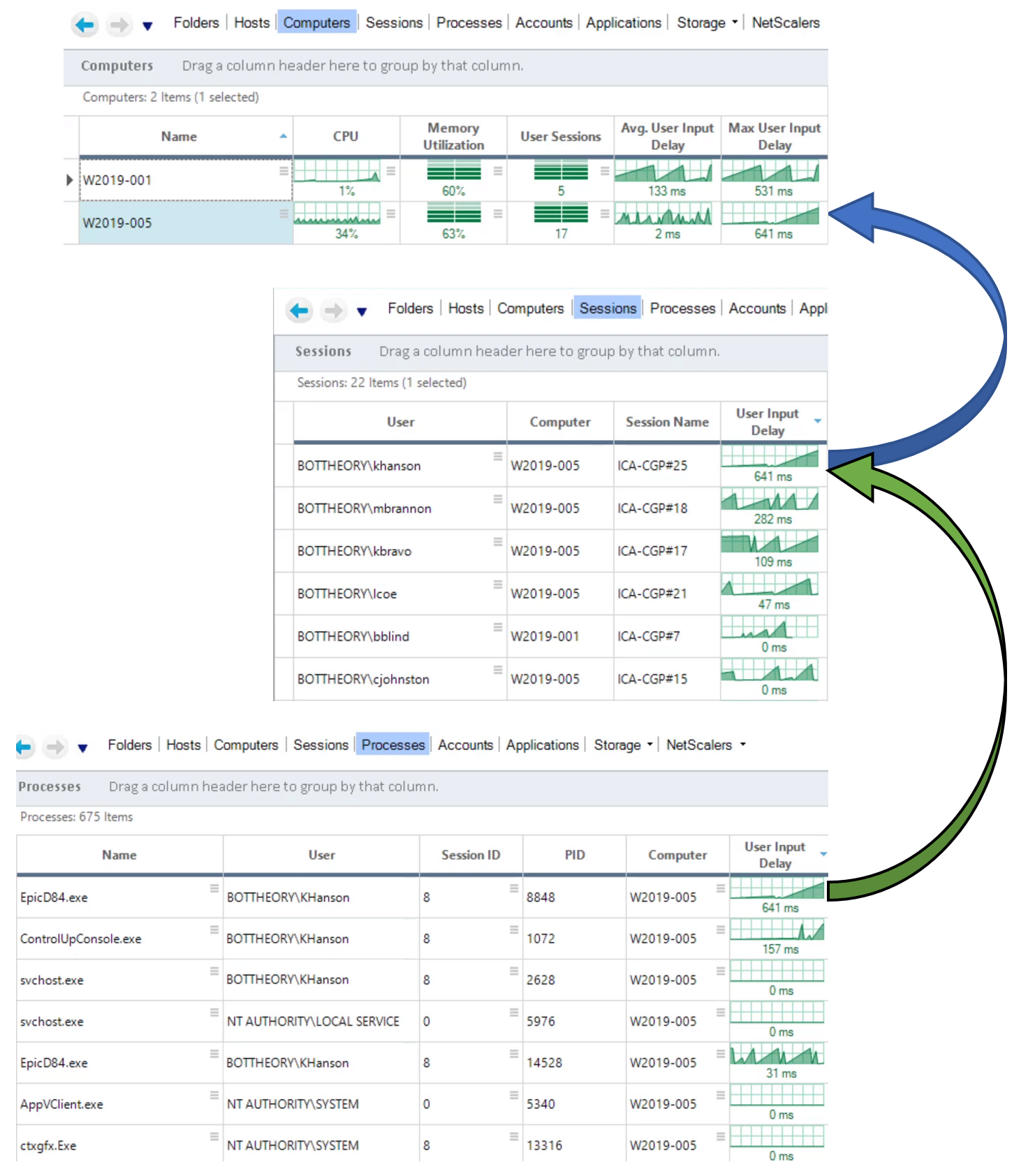
Let’s explore these values within ControlUp starting with the computers view.
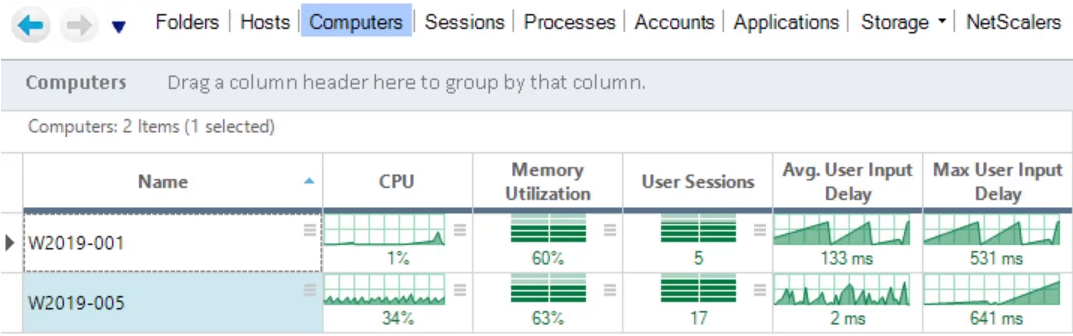
In this example, I am running two servers with some load on them. ControlUp displays the average user input delay and the maximum user input delay for all users on the servers.
We can easily see that one of the servers has longer input delays than the other. The server with longer input delays has considerably more users. It may be worth evaluating whether capping out the number of users on a server would bring the user experience to a more agreeable level.

In the sessions view, we can see which users are experiencing the most degradation in user experience. If a user were to encounter consistently high values, it would be worth talking with the user to see and profile their workflow for further optimization opportunities.
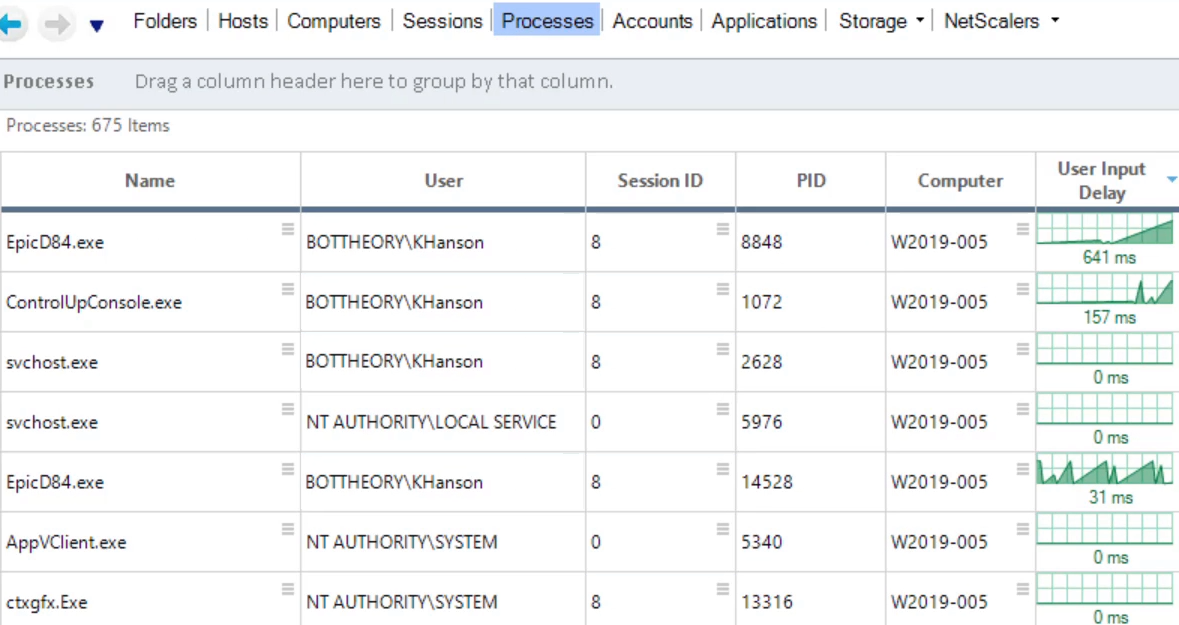
Lastly, in the process view we can see the individual processes and delays. If session sharing were enabled, you can see if the user’s session is slow overall, or if an individual process in that session is causing a slowdown.
Improving User Experience with User Input Delay
ControlUp’s Automation Platform is an incredible tool that can automate actions based on User Input Delay values. For instance, if you see a user having a poor experience as measured by User Input Delay, you can elevate the process priority, giving them more CPU cycles than their peers to improve application performance when multiple users are contending for shared resources.
The value to elevate user experience when we have shared resources is incredible. Resource contention can drag user experience down. By targeting specific applications or users bogged down by a degraded experience, you can deliver incredible value to that user and the organization, improving a single user’s experience and overall resource utilization
So let’s set up our automation.
Trigger
I’m going to create a trigger against the process record.
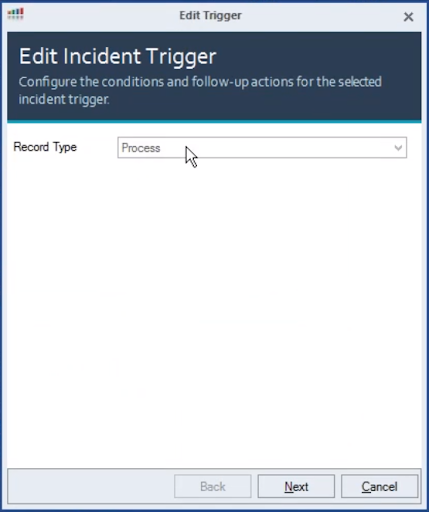
I’m going to specify the user input delay must be greater than 400ms, the process name must be one of these values, and the process priority must be Normal or lower.
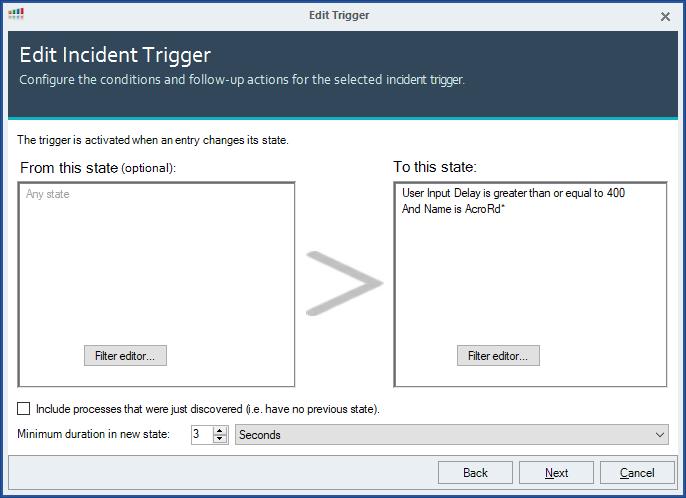
The script that will execute the process priority change is simply two lines, with the argument being passed into it being the process ID.

Lets see the automation in action.